Elasticsearch是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能;是一套开放REST和JAVA API等结构提供高效搜索功能,可扩展的分布式系统。它构建于Apache Lucene搜索引擎库之上。
本文是在学习 中华石杉老师的 Elasticsearch顶尖高手系列 的视频教程的过程中做的笔记,实际操作使用的Elasticsearch7而非视频教程中使用的版本;现在这套视频教程是免费公开的(网上直接搜索就有),强烈推荐大家去观看学习。
七、内核原理
7.1 倒排索引组成结构以及其索引不可变原因
倒排索引,是适合用于进行搜索的;倒排索引的结构:
- 包含这个关键词的document list
- 包含这个关键词的所有document的数量:IDF(inverse document frequency)
- 这个关键词在每个document中出现的次数:TF(term frequency)
- 这个关键词在这个document中的次序
- 每个document的长度:length norm
- 包含这个关键词的所有document的平均长度
word doc1 doc2
dog * *
hello *
you *倒排索引不可变的好处
- 不需要锁,提升并发能力,避免锁的问题
- 数据不变,一直保存在os cache中,只要cache内存足够
- filter cache一直驻留在内存,因为数据不变
- 可以压缩,节省cpu和io开销
倒排索引不可变的坏处:每次都要重新构建整个索引
7.2 图解剖析document写入原理(buffer,segment,commit)
基本流程
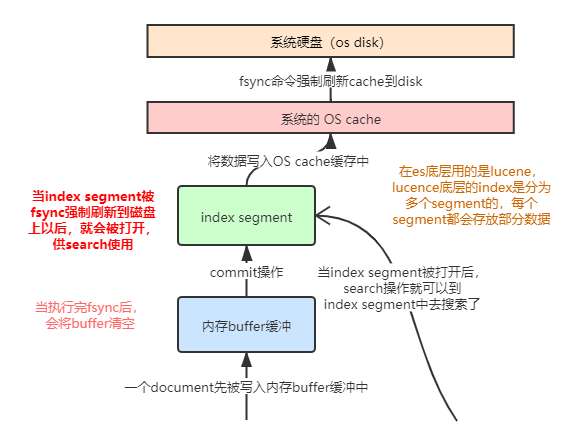
- 数据写入buffer
- commit point
- buffer中的数据写入新的index segment
- 等待在os cache中的index segment被fsync强制刷到磁盘上
- 新的index segment被打开,供search使用
- buffer被清空
每次commit point时,会有一个.del文件,标记了哪些segment中的哪些document被标记为deleted; 搜索的时候,会依次查询所有的segment,从旧的到新的,比如被修改过的document,在旧的segment中,会标记为deleted,在新的segment中会有其新的数据。
优化后的流程
在基础流程中通常写入磁盘是比较耗时,因此无法实现NTR近实时的查询。主要瓶颈在于fsync实际发生磁盘IO写数据进磁盘,是很耗时的。
写入流程别改进如下:
(1)数据写入buffer
(2)每隔一定时间,buffer中的数据被写入segment文件,但是先写入os cache
(3)只要segment写入os cache,那就直接打开供search使用,不立即执行commit
数据写入os cache,并被打开供搜索的过程,叫做refresh,默认是每隔1秒refresh一次。 也就是说,每隔一秒就会将buffer中的数据写入一个新的index segment file,先写入os cache中。 所以,es是近实时的,数据写入到可以被搜索,默认是1秒。
POST /index_demo/_refresh,可以手动refresh,一般不需要手动执行,没必要,让es自己搞就可以了
比如现在的时效性要求,比较低,只要求一条数据写入es,一分钟以后才让我们搜索到就可以了,那么就可以调整refresh interval
PUT /index_demo
{
"settings": {
"refresh_interval": "30s"
}
}最终优化流程
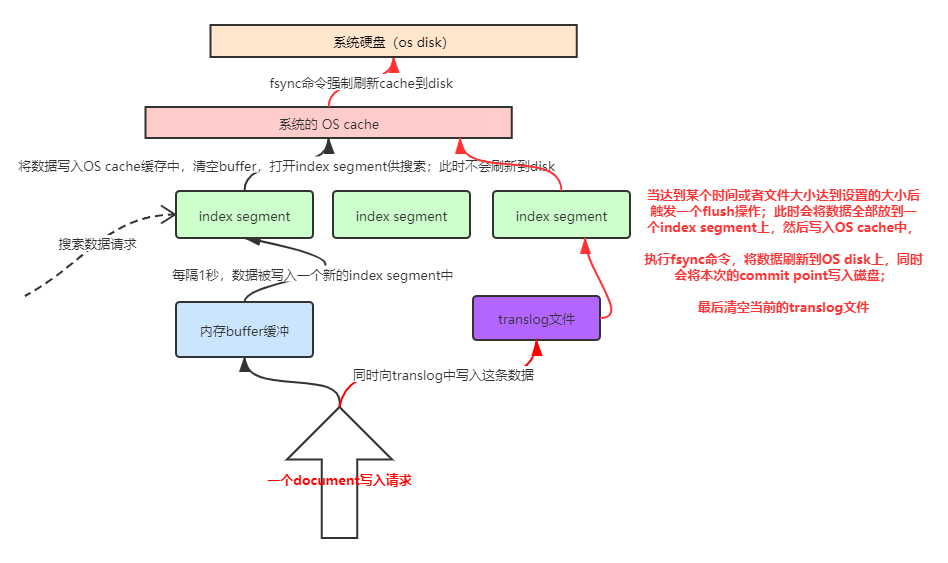
- 数据写入buffer缓冲和trans log日志文件
- 每隔一秒钟,buffer中的数据被写入新的segment file,并进入os cache,此时segment被打开并供search使用
- buffer被清空
- 重复1~3,新的segment不断添加,buffer不断被清空,而trans log中的数据不断累加
- 当trans log长度达到一定程度的时候,commit操作发生
- buffer中的所有数据写入一个新的segment,并写入os cache,打开供使用
- buffer被清空
- 一个commit point被写入磁盘,标明了所有的index segment
- filesystem cache中的所有index segment file缓存数据,被fsync强行刷到磁盘上
- 现有的trans log被清空,创建一个新的trans log
基于trans log和commit point,如何进行数据恢复
fsync+清空trans log,就是flush,默认每隔30分钟flush一次,或者当trans log过大的时候,也会flush
POST /index_demo/_flush,一般来说别手动flush,让它自动执行就可以了
trans log,每隔5秒被fsync一次到磁盘上。在一次增删改操作之后,当fsync在primary shard和replica shard都成功之后,那次增删改操作才会成功。但是这种在一次增删改时强行fsync trans log可能会导致部分操作比较耗时,也可以允许部分数据丢失,设置异步fsync trans log
PUT /index_demo/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}最后优化写入流程实现海量磁盘文件合并(segment merge,optimize)
每秒一个segment file,文件过多,而且每次search都要搜索所有的segment,很耗时。默认会在后台执行segment merge操作,在merge的时候,被标记为deleted的document也会被彻底物理删除。每次merge操作的执行流程
- 选择一些有相似大小的segment,merge成一个大的segment
- 将新的segment flush到磁盘上去
- 写一个新的commit point,包括了新的segment,并且排除旧的那些segment
- 将新的segment打开供搜索
- 将旧的segment删除
POST /index_demo/_optimize?max_num_segments=1,尽量不要手动执行,让它自动默认执行就可以了
八、Java API初步使用
CRUD
老版本(下面的方法都是过期的,在es8开始将会被移除)
引入maven依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>7.8.1</version>
</dependency>添加日志依赖(可选):
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.13.3</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.13.3</version>
</dependency>代码测试
public static void main(String[] args) throws Exception {
// 构建client
Settings settings = Settings.builder()
.put("cluster.name", "docker-cluster")
.build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new TransportAddress(InetAddress.getByName("192.168.111.40"), 9300));
//addDoc(client);
//getDoc(client);
//updateDoc(client);
delDoc(client);
client.close();
}
/**
* 添加
*/
public static void addDoc(TransportClient client) throws IOException {
IndexResponse response = client.prepareIndex("employee", "_doc", "1")
.setSource(XContentFactory.jsonBuilder()
.startObject()
.field("user", "tom")
.field("age", 18)
.field("position", "scientist")
.field("country", "China")
.field("join_data", "2020-01-01")
.field("salary", 10000)
.endObject())
.get();
System.out.println(response.getResult());
}
/**
* 查询
*/
public static void getDoc(TransportClient client){
GetResponse documentFields = client.prepareGet("employee", "_doc", "1").get();
System.out.println(documentFields.getSourceAsString());
}
/**
* 更新
*/
public static void updateDoc(TransportClient client) throws IOException {
UpdateResponse response = client.prepareUpdate("employee", "_doc", "1")
.setDoc(XContentFactory.jsonBuilder()
.startObject()
.field("salary", 1000000)
.endObject())
.get();
System.out.println(response.getResult());
}
/**
* 删除
*/
public static void delDoc(TransportClient client){
DeleteResponse response = client.prepareDelete("employee", "_doc", "1").get();
System.out.println(response);
}
/***
* 查询职位中包含scientist,并且年龄在28到40岁之间
*/
public static void search(TransportClient client){
SearchResponse response = client.prepareSearch("employee")
.setQuery(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("position", "scientist"))
.filter(QueryBuilders.rangeQuery("age").gte(28).lte(40))).setFrom(0).setSize(2).get();
System.out.println(response);
}
/***
* 聚合查询(需要重建mapping)
*/
public static void search2(TransportClient client){
SearchResponse response = client.prepareSearch("employee")
.addAggregation(AggregationBuilders.terms("group_by_country")
.field("country")
.subAggregation(AggregationBuilders.dateHistogram("group_by_join_date")
.field("joinDate")
.dateHistogramInterval(DateHistogramInterval.YEAR)
.subAggregation(AggregationBuilders.avg("avg_salary").field("salary")))
).execute().actionGet();
System.out.println(response);
}重建mapping语句:
PUT /employee
{
"mappings": {
"properties": {
"age": {
"type": "long"
},
"country": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"fielddata": true
},
"joinData": {
"type": "date"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"position": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"salary": {
"type": "long"
}
}
}
}新版本
添加maven依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.1</version>
</dependency>代码测试
public static void main(String[] args) throws IOException {
HttpHost[] httpHost = {HttpHost.create("192.168.111.40:9200")};
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(RestClient.builder(httpHost));
// addDoc(restHighLevelClient);
// getDoc(restHighLevelClient);
// updateDoc(restHighLevelClient);
delDoc(restHighLevelClient);
restHighLevelClient.close();
}
/**
* 添加
*/
public static void addDoc(RestHighLevelClient client) throws IOException {
IndexRequest request = new IndexRequest("employee");
request.id("1");
request.source(XContentFactory.jsonBuilder()
.startObject()
.field("user", "tom")
.field("age", 18)
.field("position", "scientist")
.field("country", "China")
.field("join_data", "2020-01-01")
.field("salary", 10000)
.endObject());
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
System.out.println(response.getResult());
}
/**
* 查询
*/
public static void getDoc(RestHighLevelClient client) throws IOException {
// 通过ID来查询
GetRequest request = new GetRequest("employee","1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 更丰富的查询条件
/// SearchRequest searchRequest = new SearchRequest();
/// client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
}
/**
* 更新
*/
public static void updateDoc(RestHighLevelClient client) throws IOException {
UpdateRequest request = new UpdateRequest("employee", "1");
request.doc(XContentFactory.jsonBuilder()
.startObject()
.field("salary", 1000000)
.endObject());
UpdateResponse response = client.update(request, RequestOptions.DEFAULT);
System.out.println(response.getResult());
}
/**
* 删除
*/
public static void delDoc(RestHighLevelClient client) throws IOException {
DeleteRequest request = new DeleteRequest("employee", "1");
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
System.out.println(response);
}
/**
* 查询职位中包含scientist,并且年龄在28到40岁之间
*/
public static void search(RestHighLevelClient client) throws IOException {
SearchRequest request = new SearchRequest("employee");
request.source(SearchSourceBuilder.searchSource()
.query(QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("position", "scientist"))
.filter(QueryBuilders.rangeQuery("age").gte("28").lte("28"))
).from(0).size(2)
);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
System.out.println(JSONObject.toJSONString(search.getHits()));
}九、深度探索搜索技术
9.1 使用term filter来搜索数据
准备测试数据
POST /forum/_bulk
{ "index": { "_id": 1 }}
{ "articleID" : "XHDK-A-1293-#fJ3", "userID" : 1, "hidden": false, "postDate": "2020-09-09" }
{ "index": { "_id": 2 }}
{ "articleID" : "KDKE-B-9947-#kL5", "userID" : 1, "hidden": false, "postDate": "2020-09-10" }
{ "index": { "_id": 3 }}
{ "articleID" : "JODL-X-1937-#pV7", "userID" : 2, "hidden": false, "postDate": "2020-09-09" }
{ "index": { "_id": 4 }}
{ "articleID" : "QQPX-R-3956-#aD8", "userID" : 2, "hidden": true, "postDate": "2020-09-10" }查看mapping
GET /forum/_mapping查询结果:
{
"forum": {
"mappings": {
"article": {
"properties": {
"articleID": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"hidden": {
"type": "boolean"
},
"postDate": {
"type": "date"
},
"userID": {
"type": "long"
}
}
}
}
}
}type=text,默认会设置两个field,一个是field本身,比如articleID,就是分词的;还有一个的就是field.keyword,articleID.keyword,默认不分词,会最多保留256个字符
根据用户ID搜索帖子
GET /forum/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"userID" : 1
}
}
}
}
}term filter/query:对搜索文本不分词,直接拿去倒排索引中匹配,你输入的是什么,就去匹配什么;比如如果对搜索文本进行分词的话,“helle world” –> 直接去倒排索引中匹配“hello world”;而不会去分词后再匹配。
搜索没有隐藏的帖子
GET /forum/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"hidden" : false
}
}
}
}
}根据发帖日期搜索帖子
GET /forum/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"postDate" : "2020-09-09"
}
}
}
}
}根据帖子ID搜索帖子
GET /forum/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"articleID" : "XHDK-A-1293-#fJ3"
}
}
}
}
}上面那个查询不得任何结果
GET /forum/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"articleID.keyword" : "XHDK-A-1293-#fJ3"
}
}
}
}
}第一个为什么查询不到结果?前面讲了对应类型是text的es会建立2次索引,一个是分词一个不分词(在keyword中); 使用term 进行查询时不会对其进行分词就开始查询,此时直接通过字段查询是取匹配分词的倒排索引自然也就匹配不到了;因此需要使用articleID.keyword去匹配。
articleID.keyword,是es最新版本内置建立的field,就是不分词的。所以一个articleID过来的时候,会建立两次索引,一次是自己本身,是要分词的,分词后放入倒排索引;
另外一次是基于articleID.keyword,不分词,最多保留256个字符,直接一个字符串放入倒排索引中。
term filter,对text过滤,可以考虑使用内置的field.keyword来进行匹配。但是有个问题,默认就保留256个字符,如果超过了就GG了。
所以尽可能还是自己去手动建立索引,指定not_analyzed。在最新版本的es中,不需要指定not_analyzed也可以,将type设为keyword即可。
查看分词
GET /forum/_analyze
{
"field": "articleID",
"text": "XHDK-A-1293-#fJ3"
}默认是analyzed的text类型的field,建立倒排索引的时候,会对所有的articleID分词,分词以后,原本的articleID就没有了,只有分词后的各个word存在于倒排索引中。 term,是不对搜索文本分词的,但是articleID建立索引为 xhdk,a,1293,fj3,自然直接搜索也就没得结果了。
重建索引
DELETE /forum
PUT /forum
{
"mappings": {
"properties": {
"articleID": {
"type": "keyword"
}
}
}
}执行上面的初始化数据语句,再次直接查询即可查询到结果
term filter:根据exact value进行搜索,数字、boolean、date天然支持
相当于SQL中的单个where条件
9.2 filter执行原理深度剖析(bitset机制与caching机制)
- (1)在倒排索引中查找搜索串,获取document list;
- (2)为每个在倒排索引中搜索到的结果(doc list),构建一个bitset,就是一个二进制的数组,数组每个元素都是0或1,用来标识一个doc对一个filter条件是否匹配,如果匹配就是1,不匹配就是0,类似这样:[0, 0, 0, 1, 0, 1]; 这样尽可能用简单数据结构去实现复杂的功能,可以节省内存空间,提升性能;
- (3)遍历每个过滤条件对应的bitset,优先从最稀疏的开始搜索,查找满足所有条件的document
一次性其实可以在一个search请求中,发出多个filter条件,每个filter条件都会对应一个bitset;
遍历每个filter条件对应的bitset,先从最稀疏的开始遍历
[0, 0, 0, 1, 0, 0]:比较稀疏
[0, 1, 0, 1, 0, 1]先遍历比较稀疏的bitset,就可以先过滤掉尽可能多的数据; 遍历所有的bitset,找到匹配所有filter条件的doc;就可以将document作为结果返回给client了
- (4)caching bitset,跟踪query,在最近256个query中超过一定次数的过滤条件,缓存其bitset。对于小segment(<1000,或<3%),不缓存bitset。
比如条件为postDate=2017-01-01,生成的bitset为[0, 0, 1, 1, 0, 0],可以缓存在内存中,这样下次如果再有这个条件过来的时候,就不用重新扫描倒排索引,反复生成bitset,可以大幅度提升性能。 在最近的256个filter中,有某个filter超过了一定的次数,这个次数不固定,就会自动缓存这个filter对应的bitset。
segment(分片),filter针对小segment获取到的结果,可以不缓存,segment记录数<1000,或者segment大小<index总大小的3%。 segment数据量很小时,哪怕是扫描也很快;同时segment会在后台自动合并,小segment很快就会跟其他小segment合并成大segment,此时缓存也没有什么意义,因为这些小segment合并后很快就消失了。
filter比query的好处就在于会caching,实际上并不是一个filter返回的完整的doc list数据结果。而是filter bitset缓存完整的doc list数据结果。下次不用扫描倒排索引了。
- (5)filter大部分情况下来说,在query之前执行,先尽量过滤掉尽可能多的数据
query:是会计算doc对搜索条件的relevance score,还会根据这个score去排序
filter:只是简单过滤出想要的数据,不计算relevance score,也不排序
(6)如果document有新增或修改,那么cached bitset会被自动更新;即当document有新增或修改时,会自动更新到相关filter的bitset中缓存中。
(7)以后只要是有相同的filter条件的,会直接来使用这个过滤条件对应的cached bitset即可快速将数据过滤出来返回。
9.3 基于bool组合多个filter条件来搜索数据
bool中可以通过must,must_not,should来组合多个过滤条件;bool可以嵌套,类似SQL中的and
搜索发帖日期为2020-09-09,或者帖子ID为XHDK-A-1293-#fJ3的帖子,同时要求帖子的发帖日期绝对不为2020-09-09
类似SQL如下:
SELECT
*
FROM
forum.article
WHERE
( post_date = '2020-09-09' OR article_id = 'XHDK-A-1293-#fJ3' )
AND post_date != '2020-09-10'es查询语句
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"should": [
{"term": { "postDate": "2020-09-09" }},
{"term": {"articleID": "XHDK-A-1293-#fJ3"}}
],
"must_not": {
"term": {
"postDate": "2020-09-10"
}
}
}
}
}
}
}must 必须匹配 ,should 可以匹配其中任意一个即可,must_not 必须不匹配
搜索帖子ID为XHDK-A-1293-#fJ3,或者是帖子ID为JODL-X-1937-#pV7而且发帖日期为2020-09-09的帖子
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"should": [
{
"term": {
"articleID": "XHDK-A-1293-#fJ3"
}
},
{
"bool": {
"must": [
{
"term":{
"articleID": "JODL-X-1937-#pV7"
}
},
{
"term": {
"postDate": "2020-09-09"
}
}
]
}
}
]
}
}
}
}
}9.4 使用terms搜索多个值以及多值搜索结果优化
term: {"field": "value"}
terms: {"field": ["value1", "value2"]}sql中的in
select * from tbl where col in ("value1", "value2")为帖子数据增加tag字段
POST /forum/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"tag" : ["java", "hadoop"]} }
{ "update": { "_id": "2"} }
{ "doc" : {"tag" : ["java"]} }
{ "update": { "_id": "3"} }
{ "doc" : {"tag" : ["hadoop"]} }
{ "update": { "_id": "4"} }
{ "doc" : {"tag" : ["java", "elasticsearch"]} }搜索articleID为KDKE-B-9947-#kL5或QQPX-R-3956-#aD8的帖子,
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"terms": {
"articleID": [
"KDKE-B-9947-#kL5",
"QQPX-R-3956-#aD8"
]
}
}
}
}
}搜索tag中包含java的帖子
GET /forum/_search
{
"query" : {
"constant_score" : {
"filter" : {
"terms" : {
"tag" : ["java"]
}
}
}
}
}优化搜索结果,仅仅搜索tag只包含java的帖子
现有的数据结构无法完成要求,因此我们添加一个标识字段
POST /forum/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"tag_cnt" : 2} }
{ "update": { "_id": "2"} }
{ "doc" : {"tag_cnt" : 1} }
{ "update": { "_id": "3"} }
{ "doc" : {"tag_cnt" : 1} }
{ "update": { "_id": "4"} }
{ "doc" : {"tag_cnt" : 2} }执行查询语句
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"must": [
{
"term": {
"tag_cnt": 1
}
},
{
"terms": {
"tag": ["java"]
}
}
]
}
}
}
}
}9.5 基于range filter来进行范围过滤
为帖子数据增加浏览量的字段
POST /forum/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"view_cnt" : 30} }
{ "update": { "_id": "2"} }
{ "doc" : {"view_cnt" : 50} }
{ "update": { "_id": "3"} }
{ "doc" : {"view_cnt" : 100} }
{ "update": { "_id": "4"} }
{ "doc" : {"view_cnt" : 80} }搜索浏览量在30~60之间的帖子
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"view_cnt": {
"gt": 30,
"lt": 60
}
}
}
}
}
}搜索发帖日期在最近1个月的帖子
准备示例数据
POST /forum/_bulk
{ "index": { "_id": 5 }}
{ "articleID" : "DHJK-B-1395-#Ky5", "userID" : 3, "hidden": false, "postDate": "2020-10-01", "tag": ["elasticsearch"], "tag_cnt": 1, "view_cnt": 10 }执行查询语句
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"postDate": {
"lt": "2020-10-10||-30d"
}
}
}
}
}
}
GET /forum/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"postDate": {
"gt": "now-30d"
}
}
}
}
}
}range相当于sql中的between,做范围过滤
9.6 手动控制全文检索结果的精准度
全文检索的时候,进行多个值的检索,有两种做法,match query;should;控制搜索结果精准度:and operator,minimum_should_match
为帖子数据增加标题字段
POST /forum/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"title" : "this is java and elasticsearch blog"} }
{ "update": { "_id": "2"} }
{ "doc" : {"title" : "this is java blog"} }
{ "update": { "_id": "3"} }
{ "doc" : {"title" : "this is elasticsearch blog"} }
{ "update": { "_id": "4"} }
{ "doc" : {"title" : "this is java, elasticsearch, hadoop blog"} }
{ "update": { "_id": "5"} }
{ "doc" : {"title" : "this is spark blog"} }搜索标题中包含java或elasticsearch的blog
这个和之前的那个term query不一样。不是搜索exact value,是进行全文检索(full text)。负责进行全文检索的是match query。当然,如果要检索的field,是not_analyzed类型的,那么match query也相当于term query。
GET /forum/_search
{
"query": {
"match": {
"title": "java elasticsearch"
}
}
}搜索标题中包含java和elasticsearch的
搜索结果精准控制的第一步:灵活使用and关键字,如果你是希望所有的搜索关键字都要匹配的,那么就用and,可以实现单纯match query无法实现的效果。
GET /forum/_search
{
"query": {
"match": {
"title": {
"query": "java elasticsearch",
"operator": "and"
}
}
}
}搜索包含java,elasticsearch,spark,hadoop,4个关键字中,至少3个
控制搜索结果的精准度的第二步:指定一些关键字中,必须至少匹配其中的多少个关键字,才能作为结果返回
GET /forum/_search
{
"query": {
"match": {
"title": {
"query": "java elasticsearch spark hadoop",
"minimum_should_match": "75%"
}
}
}
}用bool组合多个搜索条件,来搜索title
GET /forum/_search
{
"query": {
"bool": {
"must": {
"match": {
"title": "java"
}
},
"must_not": {
"match": {
"title": "spark"
}
},
"should": [
{
"match": {
"title": "hadoop"
}
},
{
"match": {
"title": "elasticsearch"
}
}
]
}
}
}bool组合多个搜索条件,如何计算relevance score?
must和should搜索对应的分数,加起来,除以must和should的总数
- 排名第一:java,同时包含should中所有的关键字,hadoop,elasticsearch
- 排名第二:java,同时包含should中的elasticsearch
- 排名第三:java,不包含should中的任何关键字
should是可以影响相关度分数的。must是确保谁必须有这个关键字,同时会根据这个must的条件去计算出document对这个搜索条件的relevance score。在满足must的基础之上,should中的条件,不匹配也可以,但是如果匹配的更多,那么document的relevance score就会更高。
搜索java,hadoop,spark,elasticsearch,至少包含其中3个关键字
默认情况下,should是可以不匹配任何一个的,比如上面的搜索中,this is java blog,就不匹配任何一个should条件。但是有个例外的情况,如果没有must的话,那么should中必须至少匹配一个才可以。比如下面的搜索,should中有4个条件,默认情况下,只要满足其中一个条件,就可以匹配作为结果返回。但是可以精准控制,should的4个条件中,至少匹配几个才能作为结果返回:
GET /forum/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": "java"
}
},
{
"match": {
"title": "elasticsearch"
}
},
{
"match": {
"title": "hadoop"
}
},
{
"match": {
"title": "spark"
}
}
],
"minimum_should_match": 3
}
}
}9.7 基于term+bool实现的multi word搜索底层原理剖析
普通match如何转换为term+should
{
"match": { "title": "java elasticsearch"}
}使用诸如上面的match query进行多值搜索的时候,es会在底层自动将这个match query转换为bool的语法。
bool should,指定多个搜索词,同时使用term query
{
"bool": {
"should": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }}
]
}
}and match如何转换为term+must
{
"match": {
"title": {
"query": "java elasticsearch",
"operator": "and"
}
}
}转化为:
{
"bool": {
"must": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }}
]
}
}minimum_should_match如何转换
{
"match": {
"title": {
"query": "java elasticsearch hadoop spark",
"minimum_should_match": "75%"
}
}
}转化为
{
"bool": {
"should": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }},
{ "term": { "title": "hadoop" }},
{ "term": { "title": "spark" }}
],
"minimum_should_match": 3
}
}9.8 基于boost的细粒度搜索条件权重控制
需求:
搜索标题中包含java的帖子,同时呢,如果标题中包含hadoop或elasticsearch就优先搜索出来,同时呢,如果一个帖子包含java hadoop,一个帖子包含java elasticsearch,包含hadoop的帖子要比elasticsearch优先搜索出来
知识点:
搜索条件的权重,boost,可以将某个搜索条件的权重加大,此时当匹配这个搜索条件和匹配另一个搜索条件的document, 计算relevance score时,匹配权重更大的搜索条件的document,relevance score会更高,当然也就会优先被返回回来。 默认情况下,搜索条件的权重是相同的,都是1
GET /forum/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "java"
}
}
],
"should": [
{
"match": {
"title": {
"query": "elasticsearch"
}
}
},
{
"match": {
"title": {
"query": "hadoop",
"boost": 5
}
}
}
]
}
}
}9.9 多shard场景下relevance score不准确问题
多shard场景下relevance score不准确问题
如果你的一个index有多个shard的话,可能搜索结果会不准确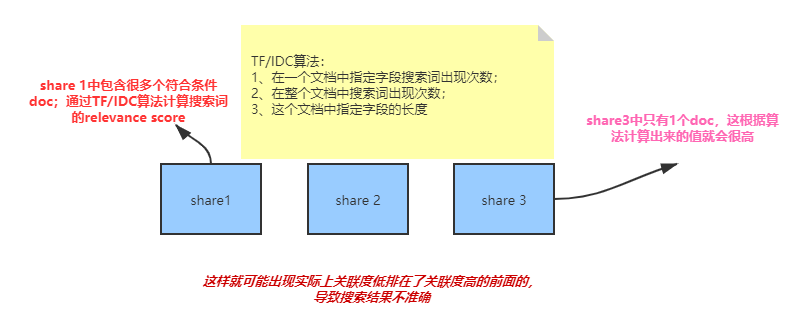
如何解决该问题?
- (1)生产环境下,数据量大,尽可能实现均匀分配
数据量很大的话,其实一般情况下,在概率学的背景下,es都是在多个shard中均匀路由数据的,路由的时候根据_id,负载均衡 比如说有10个document,title都包含java,一共有5个shard,那么在概率学的背景下,如果负载均衡的话,其实每个shard都应该有2个doc,title包含java。如果数据分布均匀的话,其实就没有刚才说的那个问题了。
- (2)测试环境下,将索引的primary shard设置为1个,number_of_shards=1,index settings
如果只有一个shard,所有的document都在这个shard里面,也就没有这个问题了
- (3)测试环境下,搜索附带search_type=dfs_query_then_fetch参数,会将local IDF取出来计算global IDF
计算一个doc的相关度分数的时候,就会将所有shard对local IDF计算一下获取出来,然后在本地进行global IDF分数的计算,之后将所有shard的doc作为上下文来进行计算,也能确保准确性。但是production生产环境下,不推荐这个参数,因为性能很差。
9.10 基于dis_max实现best fields策略进行多字段搜索
为帖子数据增加content字段
POST /forum/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"content" : "i like to write best elasticsearch article"} }
{ "update": { "_id": "2"} }
{ "doc" : {"content" : "i think java is the best programming language"} }
{ "update": { "_id": "3"} }
{ "doc" : {"content" : "i am only an elasticsearch beginner"} }
{ "update": { "_id": "4"} }
{ "doc" : {"content" : "elasticsearch and hadoop are all very good solution, i am a beginner"} }
{ "update": { "_id": "5"} }
{ "doc" : {"content" : "spark is best big data solution based on scala ,an programming language similar to java"} }搜索title或content中包含java或solution的帖子
GET /forum/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]
}
}
}搜索结果分析
期望的是doc5,结果是doc2,doc4排在了前面。计算每个document的relevance score:每个query的分数,乘以matched query数量,除以总query数量
- 算一下doc4的分数
{ "match": { "title": "java solution" }},针对doc4,是有一个分数的 { "match": { "content": "java solution" }},针对doc4,也是有一个分数的
所以是两个分数加起来,比如说,1.1 + 1.2 = 2.3;matched query数量 = 2;总query数量 = 2;即:2.3 * 2 / 2 = 2.3
- 算一下doc5的分数
{ "match": { "title": "java solution" }},针对doc5,是没有分数的
{ "match": { "content": "java solution" }},针对doc5,是有一个分数的只有一个query是有分数的,比如2.3;matched query数量 = 1;总query数量 = 2;即:2.3 * 1 / 2 = 1.15。doc5的分数 = 1.15 < doc4的分数 = 2.3
best fields策略,dis_max
best fields策略,搜索到的结果,应该是某一个field中匹配到了尽可能多的关键词,被排在前面;而不是尽可能多的field匹配到了少数的关键词,排在了前面。
dis_max语法,直接取多个query中,分数最高的那一个query的分数即可
{ "match": { "title": "java solution" }},针对doc4,是有一个分数的,1.1
{ "match": { "content": "java solution" }},针对doc4,也是有一个分数的,1.2取最大分数,1.2
{ "match": { "title": "java solution" }},针对doc5,是没有分数的
{ "match": { "content": "java solution" }},针对doc5,是有一个分数的,2.3取最大分数,2.3。然后doc4的分数 = 1.2 < doc5的分数 = 2.3,所以doc5就可以排在更前面的地方,符合我们的需要
GET /forum/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java solution" }},
{ "match": { "content": "java solution" }}
]
}
}
}9.11 基于tie_breaker参数优化dis_max搜索效果
搜索title或content中包含java beginner的帖子
GET /forum/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java beginner" }},
{ "match": { "body": "java beginner" }}
]
}
}
}可能在实际场景中出现的一个情况是这样的:
- (1)某个帖子,doc1,title中包含java,content不包含java beginner任何一个关键词
- (2)某个帖子,doc2,content中包含beginner,title中不包含任何一个关键词
- (3)某个帖子,doc3,title中包含java,content中包含beginner
- (4)最终搜索,可能出来的结果是,doc1和doc2排在doc3的前面,而不是我们期望的doc3排在最前面
dis_max,只是取分数最高的那个query的分数而已
dis_max只取某一个query最大的分数,完全不考虑其他query的分数
使用tie_breaker将其他query的分数也考虑进去
tie_breaker参数的意义,在于将其他query的分数,乘以tie_breaker,然后综合与最高分数的那个query的分数,综合在一起进行计算;除了取最高分以外,还会考虑其他的query的分数;tie_breaker的值,在0~1之间,是个小数,就ok
GET /forum/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "java beginner" }},
{ "match": { "body": "java beginner" }}
],
"tie_breaker": 0.3
}
}
}9.12 基于multi_match语法实现dis_max+tie_breaker
GET /forum/_search
{
"query": {
"multi_match": {
"query": "java solution",
"type": "best_fields",
"fields": [ "title^2", "content" ],
"tie_breaker": 0.3,
"minimum_should_match": "50%"
}
}
}
GET /forum/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"title": {
"query": "java beginner",
"minimum_should_match": "50%",
"boost": 2
}
}
},
{
"match": {
"body": {
"query": "java beginner",
"minimum_should_match": "30%"
}
}
}
],
"tie_breaker": 0.3
}
}
}minimum_should_match,主要是用来干嘛的?
去长尾 long tail,什么是长尾,比如你搜索5个关键词,但是很多结果只匹配1个关键词,其实跟你想要的结果相差甚远,这些结果就是长尾; minimum_should_match,控制搜索结果的精准度,只有匹配一定数量的关键词的数据,才能返回
9.13 基于multi_match+most fields策略进行multi-field搜索
从best-fields换成most-fields策略;best-fields策略,主要是将某一个field匹配尽可能多的关键词的doc优先返回回来 ;most-fields策略,主要是尽可能返回更多field匹配到某个关键词的doc,优先返回回来
POST /forum/_mapping
{
"properties": {
"sub_title": {
"type": "text",
"analyzer": "english",
"fields": {
"std": {
"type": "text",
"analyzer": "standard"
}
}
}
}
}
POST /forum/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"sub_title" : "learning more courses"} }
{ "update": { "_id": "2"} }
{ "doc" : {"sub_title" : "learned a lot of course"} }
{ "update": { "_id": "3"} }
{ "doc" : {"sub_title" : "we have a lot of fun"} }
{ "update": { "_id": "4"} }
{ "doc" : {"sub_title" : "both of them are good"} }
{ "update": { "_id": "5"} }
{ "doc" : {"sub_title" : "haha, hello world"} }
GET /forum/_search
{
"query": {
"match": {
"sub_title": "learning courses"
}
}
}sub_title用的是english analyzer,所以还原了单词
为什么,因为如果我们用的是类似于english analyzer这种分词器的话,就会将单词还原为其最基本的形态,stemmer
learning --> learn
learned --> learn
courses --> course
GET /forum/_search
{
"query": {
"multi_match": {
"query": "learning courses",
"type": "most_fields",
"fields": [ "sub_title", "sub_title.std" ]
}
}
}与best_fields的区别
- (1)best_fields,是对多个field进行搜索,挑选某个field匹配度最高的那个分数,同时在多个query最高分相同的情况下,在一定程度上考虑其他query的分数。 简单来说,你对多个field进行搜索,就想搜索到某一个field尽可能包含更多关键字的数据。
优点:通过best_fields策略,以及综合考虑其他field,还有minimum_should_match支持,可以尽可能精准地将匹配的结果推送到最前面。
缺点:除了那些精准匹配的结果,其他差不多大的结果,排序结果不是太均匀,没有什么区分度了。
实际的例子:百度之类的搜索引擎,最匹配的到最前面,但是其他的就没什么区分度了
- (2)most_fields,综合多个field一起进行搜索,尽可能多地让所有field的query参与到总分数的计算中来,此时就会是个大杂烩,出现类似best_fields案例最开始的那个结果,结果不一定精准,某一个document的一个field包含更多的关键字,但是因为其他document有更多field匹配到了,所以排在了前面;因此需要建立类似sub_title.std这样的field,尽可能让某一个field精准匹配query string,贡献更高的分数,将更精准匹配的数据排到前面
优点:将尽可能匹配更多field的结果推送到最前面,整个排序结果是比较均匀的;
缺点:可能那些精准匹配的结果,无法推送到最前面
实际的例子:wiki,明显的most_fields策略,搜索结果比较均匀,但是的确要翻好几页才能找到最匹配的结果
9.14 使用most_fields策略进行cross-fields search弊端
cross-fields搜索,一个唯一标识,跨了多个field。比如一个人,标识,是姓名;一个建筑,它的标识是地址。姓名可以散落在多个field中,比如first_name和last_name中,地址可以散落在country,province,city中。
跨多个field搜索一个标识,比如搜索一个人名,或者一个地址,就是cross-fields搜索
初步来说,如果要实现,可能用most_fields比较合适。因为best_fields是优先搜索单个field最匹配的结果,cross-fields本身就不是一个field的问题了。
POST /forum/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"author_first_name" : "Peter", "author_last_name" : "Smith"} }
{ "update": { "_id": "2"} }
{ "doc" : {"author_first_name" : "Smith", "author_last_name" : "Williams"} }
{ "update": { "_id": "3"} }
{ "doc" : {"author_first_name" : "Jack", "author_last_name" : "Ma"} }
{ "update": { "_id": "4"} }
{ "doc" : {"author_first_name" : "Robbin", "author_last_name" : "Li"} }
{ "update": { "_id": "5"} }
{ "doc" : {"author_first_name" : "Tonny", "author_last_name" : "Peter Smith"} }
GET /forum/_search
{
"query": {
"multi_match": {
"query": "Peter Smith",
"type": "most_fields",
"fields": [ "author_first_name", "author_last_name" ]
}
}
}Peter Smith,匹配author_first_name,匹配到了Smith,这时候它的分数很高,为什么啊???
因为IDF分数高,IDF分数要高,那么这个匹配到的term(Smith),在所有doc中的出现频率要低,author_first_name field中,Smith就出现过1次。Peter Smith这个人,doc 1,Smith在author_last_name中,但是author_last_name出现了两次Smith,所以导致doc 1的IDF分数较低。
问题1:只是找到尽可能多的field匹配的doc,而不是某个field完全匹配的doc
问题2:most_fields,没办法用minimum_should_match去掉长尾数据,就是匹配的特别少的结果
问题3:TF/IDF算法,比如Peter Smith和Smith Williams,搜索Peter Smith的时候,由于first_name中很少有Smith的,所以query在所有document中的频率很低,得到的分数很高,可能Smith Williams反而会排在Peter Smith前面
9.15 使用copy_to定制组合field解决cross-fields搜索弊端
上一讲,我们说了用most_fields策略,去实现cross-fields搜索,有3大弊端,而且搜索结果也显示出了这3大弊端
第一个办法:用copy_to,将多个field组合成一个field。问题其实就出在有多个field,有多个field以后,就很尴尬,我们要想办法将一个标识跨在多个field的情况,合并成一个field。 比如说,一个人名,本来是first_name,last_name,现在合并成一个full_name,这样就直接查full_name 就ok了。
PUT /forum/_mapping
{
"properties": {
"new_author_first_name": {
"type": "text",
"copy_to": "new_author_full_name"
},
"new_author_last_name": {
"type": "text",
"copy_to": "new_author_full_name"
},
"new_author_full_name": {
"type": "text"
}
}
}用了这个copy_to语法之后,就可以将多个字段的值拷贝到一个字段中,并建立倒排索引
POST /forum/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"new_author_first_name" : "Peter", "new_author_last_name" : "Smith"} }
{ "update": { "_id": "2"} }
{ "doc" : {"new_author_first_name" : "Smith", "new_author_last_name" : "Williams"} }
{ "update": { "_id": "3"} }
{ "doc" : {"new_author_first_name" : "Jack", "new_author_last_name" : "Ma"} }
{ "update": { "_id": "4"} }
{ "doc" : {"new_author_first_name" : "Robbin", "new_author_last_name" : "Li"} }
{ "update": { "_id": "5"} }
{ "doc" : {"new_author_first_name" : "Tonny", "new_author_last_name" : "Peter Smith"} }
GET /forum/_search
{
"query": {
"match": {
"new_author_full_name": "Peter Smith"
}
}
}问题1:只是找到尽可能多的field匹配的doc,而不是某个field完全匹配的doc –> 解决,最匹配的document被最先返回
问题2:most_fields,没办法用minimum_should_match去掉长尾数据,就是匹配的特别少的结果 –> 解决,可以使用minimum_should_match去掉长尾数据
问题3:TF/IDF算法,比如Peter Smith和Smith Williams,搜索Peter Smith的时候,由于first_name中很少有Smith的,所以query在所有document中的频率很低,得到的分数很高,可能Smith Williams反而会排在Peter Smith前面 –> 解决,Smith和Peter在一个field了,所以在所有document中出现的次数是均匀的,不会有极端的偏差
9.16 使用原生cross-fields技术解决搜索弊端
GET /forum/_search
{
"query": {
"multi_match": {
"query": "Peter Smith",
"type": "cross_fields",
"operator": "and",
"fields": ["author_first_name", "author_last_name"]
}
}
} 问题1:只是找到尽可能多的field匹配的doc,而不是某个field完全匹配的doc –> 解决,要求每个term都必须在任何一个field中出现
问题2:most_fields,没办法用minimum_should_match去掉长尾数据,就是匹配的特别少的结果 –> 解决,既然每个term都要求出现,长尾肯定被去除掉了
问题3:TF/IDF算法,比如Peter Smith和Smith Williams,搜索Peter Smith的时候,由于first_name中很少有Smith的,
所以query在所有document中的频率很低,得到的分数很高,可能Smith Williams反而会排在Peter Smith前面 –> 计算IDF的时候,将每个query在每个field中的IDF都取出来,取最小值,就不会出现极端情况下的极大值了
9.17 掌握phrase matching搜索技术
如果我们要尽量让java和spark离的很近的document优先返回,要给它一个更高的relevance score,这就涉及到了proximity match,近似匹配。
需求:
- java spark,就靠在一起,中间不能插入任何其他字符,就要搜索出来这种doc
- java spark,但是要求,java和spark两个单词靠的越近,doc的分数越高,排名越靠前
要实现上述两个需求,用match做全文检索,是搞不定的,必须得用proximity match,近似匹配
phrase match,proximity match:短语匹配,近似匹配
使用match_phrase来查询包含java and elasticsearch的数据
POST /forum/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"content" : "java elasticsearch is friend"} }
{ "update": { "_id": "2"} }
{ "doc" : {"content" : "java and elasticsearch very good"} }
{ "update": { "_id": "3"} }
{ "doc" : {"content" : "this is elasticsearch blog"} }
{ "update": { "_id": "4"} }
{ "doc" : {"content" : "this is java, elasticsearch, hadoop blog"} }
{ "update": { "_id": "5"} }
{ "doc" : {"content" : "this is spark blog"} }使用match_phrase来查询包含java and elasticsearch的数据
GET /forum/_search
{
"query": {
"match_phrase": {
"content": "java and elasticsearch"
}
}
}match_phrase的基本原理
这里举个简单例子来说明;有如下2个文档内容,我们需要 match_phrase匹配的是java elasticsearch
doc1 : hello, java elasticsearch
doc2 : hello, elasticsearch java首先对文档内容建立类似如下的倒排索引,在value中保存了term(单词)的position(位置)
hello -------------- [doc1(1), doc2(1)]
java --------------- [doc1(2), doc2(3)]
elasticsearch ------ [doc1(3), doc2(2)]这样在查询时先对查询的内容java elasticsearch进行分词得到java、elasticsearch然后根据倒排索引进行查询得到匹配的文档doc1,doc2; 现在对数据进一步做匹配处理:
doc1–>> java-doc1(2),elasticsearch-doc1(3);elasticsearch的position刚好比java的大1,符合实际的顺序,doc1 符合条件;
doc2–>> java-doc2(3),elasticsearch-doc2(2);elasticsearch的position比java的小1,不符合实际的顺序,doc2 不符合条件;
最终只有doc1符合条件。
9.18 基于slop参数实现近似匹配以及原理剖析和相关实验
GET /forum/_search
{
"query": {
"match_phrase": {
"content": {
"query": "java elasticsearch",
"slop": 1
}
}
}
}slop的含义:query string,搜索文本中的几个term,要经过几次移动才能与一个document匹配,这个移动的次数,就是slop;
这里设置slop的意思就是在匹配的过程中最多可以移动多少次;
其实,加了slop的phrase match,就是proximity match,近似匹配
9.19 混合使用match和近似匹配实现召回率与精准度的平衡
召回率:搜索一个java elasticsearch,总共有100个doc,能返回多少个doc作为结果,就是召回率(recall)
精准度:搜索一个java elasticsearch,能不能尽可能让包含java elasticsearch,或者是java和elasticsearch离的很近的doc,排在最前面,就是精准度(precision)
直接用match_phrase短语搜索,会导致必须所有term都在doc field中出现,而且距离在slop限定范围内,才能匹配上
match phrase和proximity match要求doc必须包含所有的term,才能作为结果返回;如果某一个doc可能就是有某个term没有包含,那么就无法作为结果返回。
近似匹配的时候,召回率比较低,精准度太高了
但是有时我们希望的是匹配到几个term中的部分,就可以作为结果出来,这样可以提高召回率。 同时我们也希望用上match_phrase根据距离提升分数的功能,让几个term距离越近分数就越高,优先返回。 就是优先满足召回率意思,比如搜索java elasticsearch,包含java的也返回,包含elasticsearch的也返回,包含java和elasticsearch的也返回; 同时兼顾精准度,就是包含java和elasticsearch,同时java和elasticsearch离的越近的doc排在最前面
此时可以用bool组合match query和match_phrase query一起,来实现上述效果
GET /forum/_search
{
"query": {
"bool": {
"must": {
"match": {
"content": {
"query": "java elasticsearch"
}
}
},
"should": {
"match_phrase": {
"content": {
"query": "java elasticsearch",
"slop": 50
}
}
}
}
}
}在match query中java或elasticsearch或java elasticsearch,java和elasticsearch靠前,但是没法区分java和elasticsearch的距离,也许java和elasticsearch靠的很近,但是没法排在最前面
match_phrase在slop以内,如果java elasticsearch能匹配上一个doc,那么就会对doc贡献自己的relevance score,如果java和elasticsearch靠的越近,那么就分数越高
9.20 使用rescoring机制优化近似匹配搜索的性能
match和phrase match(proximity match)区别
match: 只要简单的匹配到了一个term,就可以理解将term对应的doc作为结果返回,扫描倒排索引,扫描到了就ok
phrase match :首先扫描到所有term的doc list; 找到包含所有term的doc list; 然后对每个doc都计算每个term的position,是否符合指定的范围; slop,需要进行复杂的运算,来判断能否通过slop移动,匹配一个doc
match query的性能比phrase match和proximity match(有slop)要高很多。因为后两者都要计算position的距离。 match query比phrase match的性能要高10倍,比proximity match的性能要高20倍。
但是别太担心,因为es的性能一般都在毫秒级别,match query一般就在几毫秒,或者几十毫秒,而phrase match和proximity match的性能在几十毫秒到几百毫秒之间,所以也是可以接受的。
优化proximity match的性能,一般就是减少要进行proximity match搜索的document数量。 主要思路就是,用match query先过滤出需要的数据,然后再用proximity match来根据term距离提高doc的分数, 同时proximity match只针对每个shard的分数排名前n个doc起作用,来重新调整它们的分数,这个过程称之为重计分(rescoring)。 因为一般用户会分页查询,只会看到前几页的数据,所以不需要对所有结果进行proximity match操作。
用我们刚才的说法,match + proximity match同时实现召回率和精准度
默认情况下,match也许匹配了1000个doc,proximity match全都需要对每个doc进行一遍运算,判断能否slop移动匹配上,然后去贡献自己的分数。但是很多情况下,match出来也许1000个doc,其实用户大部分情况下是分页查询的,所以可能最多只会看前几页,比如一页是10条,最多也许就看5页,就是50条。proximity match只要对前50个doc进行slop移动去匹配,去贡献自己的分数即可,不需要对全部1000个doc都去进行计算和贡献分数
GET /forum/_search
{
"query": {
"match": {
"content": "java elasticsearch"
}
},
"rescore": {
"window_size": 50,
"query": {
"rescore_query": {
"match_phrase": {
"content": {
"query": "java elasticsearch",
"slop": 50
}
}
}
}
}
}9.21 实战前缀搜索、通配符搜索、正则搜索等技术
前缀搜索
GET /forum/_search
{
"query": {
"prefix": {
"articleID.keyword": {
"value": "X"
}
}
}
}前缀搜索的原理:prefix query不计算relevance score,与prefix filter唯一的区别就是,filter会cache bitset;扫描整个倒排索引。前缀越短,要处理的doc越多,性能越差,尽可能用长前缀搜索
前缀搜索,它是怎么执行的?性能为什么差呢?
根据前缀扫描完整个的倒排索引,一个个匹配将结果返回,这就是为什么性能差
通配符搜索
跟前缀搜索类似,使用通配符去表达更加复杂的模糊搜索的语义,功能更加强大
5?-*5:5个字符 D 任意个字符5
GET /forum/_search
{
"query": {
"wildcard": {
"articleID": {
"value": "X?K*5"
}
}
}
}?:任意字符; *:0个或任意多个字符
性能一样差,必须扫描整个倒排索引
正则搜索
GET /forum/_search
{
"query": {
"regexp": {
"articleID": "X[0-9].+"
}
}
}wildcard和regexp,与prefix原理一致,都会扫描整个索引,性能很差
9.22 实战match_phrase_prefix实现search-time搜索推荐
GET /forum/_search
{
"query": {
"match_phrase_prefix": {
"content": "java e"
}
}
}原理跟match_phrase类似,唯一的区别,就是把最后一个term作为前缀去搜索。大致流程:
- 搜索
java e会先分词为java、e; - 然后java会进行match搜索对应的doc;
- e会作为前缀,去扫描整个倒排索引,找到所有w开头的doc;
- 然后找到所有doc中,即包含java,又包含e开头的字符的doc; 根据你的slop去计算,看在slop范围内,能不能让java e, 正好跟doc中的java和e开头的单词的position相匹配;也可以指定slop,但是只有最后一个term会作为前缀。
max_expansions:指定prefix最多匹配多少个term,超过这个数量就不继续匹配了,限定性能。
默认情况下,前缀要扫描所有的倒排索引中的term,去查找e打头的单词,但是这样性能太差。可以用max_expansions限定,e前缀最多匹配多少个term,就不再继续搜索倒排索引了。尽量不要用,因为,最后一个前缀始终要去扫描大量的索引,性能可能会很差。
9.23 实战通过ngram分词机制实现index-time搜索推荐
ngram和index-time搜索推荐原理
什么是ngram?按词语可以拆分的长度进行处理,下面举例说明:
quick,5种长度下的ngram
ngram length=1,q u i c k
ngram length=2,qu ui ic ck
ngram length=3,qui uic ick
ngram length=4,quic uick
ngram length=5,quick什么是edge ngram?固定首字母,然后依次叠加词;下面举例说明: quick,根据首字母后进行ngram
q
qu
qui
quic
quick使用edge ngram将每个单词都进行进一步的分词切分,用切分后的ngram来实现前缀搜索推荐功能。搜索的时候,不用再根据一个前缀,然后扫描整个倒排索引了; 直接拿前缀去倒排索引中匹配即可,如果匹配上了,那么就好了。
ngram示例
设置ngram
PUT /ngram-demo
{
"settings": {
"analysis": {
"filter": {
"autocomplete_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 20
}
},
"analyzer": {
"autocomplete": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"autocomplete_filter"
]
}
}
}
}
}查看分词
GET /ngram-demo/_analyze
{
"analyzer": "autocomplete",
"text": "quick brown"
}_mapping设置
PUT /ngram-demo/_mapping
{
"properties": {
"title": {
"type": "text",
"analyzer": "autocomplete",
"search_analyzer": "standard"
}
}
}添加测试数据
POST /ngram-demo/_bulk
{ "index": { "_id": 1 }}
{ "title" : "hello wiki", "userID" : 1, "hidden": false }数据查询
GET /ngram-demo/_search
{
"query": {
"match_phrase": {
"title": "hello w"
}
}
}如果用match,只有hello的也会出来,全文检索,只是分数比较低;推荐使用match_phrase,要求每个term都有,而且position刚好靠着1位,符合我们的期望的
9.24 深入揭秘TF&IDF算法以及向量空间模型算法
boolean model:
类似and这种逻辑操作符,先过滤出包含指定term的doc;比如:
query "hello world" --> 过滤 --> hello / world / hello & world
bool --> must/must not/should --> 过滤 --> 包含 / 不包含 / 可能包含
doc --> 不打分数 --> 正或反 true or false --> 为了减少后续要计算的doc的数量,提升性能单个term在doc中的分数
- TF/IDF: 一个term在一个doc中,根据出现的次数给个分数,出现的次数越多,那么最后给的相关度评分就会越高
- IDF:inversed document frequency;一个term在所有的doc中,出现的次数越多,那么最后给的相关度评分就会越低
- length norm:搜索的那个field内容的长度,field长度越长,给的相关度评分越低; field长度越短,给的相关度评分越高 。最后,会将这个term,对doc1的分数,综合TF,IDF,length norm,计算出来一个综合性的分数
- vector space model:多个term对一个doc的总分数
es会根据搜索词语在所有doc中的评分情况,计算出一个query vector(query向量); 会给每一个doc,拿每个term计算出一个分数来,再拿所有term的分数组成一个doc vector; 画在一个图中,取每个doc vector对query vector的弧度,给出每个doc对多个term的总分数 每个doc vector计算出对query vector的弧度,最后基于这个弧度给出一个doc相对于query中多个term的总分数;弧度越大,分数月底; 弧度越小,分数越高。如果是多个term,那么就是线性代数来计算,无法用图表示
9.25 实战掌握四种常见的相关度分数优化方法
query-time boost
GET /forum/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title": {
"query": "java spark",
"boost": 2
}
}
},
{
"match": {
"content": "java spark"
}
}
]
}
}
}重构查询结构
重构查询结果,在es新版本中,影响越来越小了。一般情况下,没什么必要的话,大家不用也行。
GET /forum/article/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"content": "java"
}
},
{
"match": {
"content": "spark"
}
},
{
"bool": {
"should": [
{
"match": {
"content": "solution"
}
},
{
"match": {
"content": "beginner"
}
}
]
}
}
]
}
}
}negative boost降低相关度
GET /forum/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"content": "java"
}
},
"negative": {
"match": {
"content": "spark"
}
},
"negative_boost": 0.2
}
}
}negative的doc,会乘以negative_boost,降低分数
constant_score
如果你压根儿不需要相关度评分,直接走constant_score加filter,所有的doc分数都是1,没有评分的概念了
GET /forum/_search
{
"query": {
"bool": {
"should": [
{
"constant_score": {
"query": {
"match": {
"title": "java"
}
}
}
},
{
"constant_score": {
"query": {
"match": {
"title": "spark"
}
}
}
}
]
}
}
}9.26 实战用function_score自定义相关度分数算法
我们可以做到自定义一个function_score函数,自己将某个field的值,跟es内置算出来的分数进行运算,然后由自己指定的field来进行分数的增强
数据准备
POST /forum/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"follower_num" : 5} }
{ "update": { "_id": "2"} }
{ "doc" : {"follower_num" : 10} }
{ "update": { "_id": "3"} }
{ "doc" : {"follower_num" : 25} }
{ "update": { "_id": "4"} }
{ "doc" : {"follower_num" : 3} }
{ "update": { "_id": "5"} }
{ "doc" : {"follower_num" : 60} }将搜索得到的分数,跟follower_num进行运算,由follower_num在一定程度上增强其分数;follower_num越大,那么分数就越高
GET /forum/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "java spark",
"fields": ["tile", "content"]
}
},
"field_value_factor": {
"field": "follower_num",
"modifier": "log1p",
"factor": 0.5
},
"boost_mode": "sum",
"max_boost": 2
}
}
}如果只有field,那么会将每个doc的分数都乘以follower_num,如果有的doc follower是0,那么分数就会变为0,效果很不好。 因此一般会加个log1p函数,公式会变为,new_score = old_score * log(1 + number_of_votes),这样出来的分数会比较合理; 再加个factor,可以进一步影响分数,new_score = old_score * log(1 + factor * number_of_votes); boost_mode,可以决定分数与指定字段的值如何计算,multiply,sum,min,max,replace; max_boost,限制计算出来的分数不要超过max_boost指定的值。
9.27 实战掌握误拼写时的fuzzy模糊搜索技术
搜索的时候,可能输入的搜索文本会出现误拼写的情况;fuzzy搜索技术 –> 自动将拼写错误的搜索文本,进行纠正,纠正以后去尝试匹配索引中的数据。
实际想要hello,但是少写个o
GET /forum/_search
{
"query": {
"fuzzy": {
"title": {
"value": "hell",
"fuzziness": 2
}
}
}
}fuzziness 指定的修订最大次数,默认为2
GET /forum/_search
{
"query": {
"match": {
"title": {
"query": "helio",
"fuzziness": "AUTO",
"operator": "and"
}
}
}
}十、IK中文分词器
安装
从github上下载安装包(或者自己编译):
https://github.com/medcl/elasticsearch-analysis-ik将解压后的文件放到es的docker容器中(也可以做个文件目录的映射):
docker cp /home/ik es7:/usr/share/elasticsearch/plugins/ik目录就是解压后的文件目录
如果不确定plugins目录在哪儿,可以通过docker exec -it es7 /bin/bash命令进入容器内查看
然后重启es
docker restart es7ik分词器基础知识
两种analyzer,根据自己的需要选择,但是一般是选用ik_max_word
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
ik分词器的使用
配置mapping:
PUT /news
{
"mappings": {
"properties": {
"content":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}IK分词器配置文件讲解以及自定义词库
- IKAnalyzer.cfg.xml:用来配置自定义词库
- main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起
- quantifier.dic:放了一些单位相关的词
- suffix.dic:放了一些后缀
- surname.dic:中国的姓氏
- stopword.dic:英文停用词
ik原生最重要的两个配置文件
- main.dic:包含了原生的中文词语,会按照这个里面的词语去分词
- stopword.dic:包含了英文的停用词,停用词,stopword。一般,像停用词,会在分词的时候,直接被干掉,不会建立在倒排索引中
自定义词库
(1)自己建立词库:每年都会涌现一些特殊的流行词,网红,蓝瘦香菇,喊麦,鬼畜,一般不会在ik的原生词典里
自己补充自己的最新的词语,到ik的词库里面去;在IKAnalyzer.cfg.xml中配置自定义的词,ext_dict,custom/mydict.dic 。补充自己的词语,然后需要重启es,才能生效
(2)自己建立停用词库:比如了,的,啥,么,我们可能并不想去建立索引,让人家搜索 custom/ext_stopword.dic,已经有了常用的中文停用词,可以补充自己的停用词,然后重启es
修改IK分词器源码来基于mysql热更新词库
热更新
每次都是在es的扩展词典中,手动添加新词语,很坑
(1)每次添加完,都要重启es才能生效,非常麻烦
(2)es是分布式的,可能有数百个节点,你不能每次都一个一个节点上面去修改
es不停机,直接我们在外部某个地方添加新的词语,es中立即热加载到这些新词语
热更新的方案
(1)修改ik分词器源码,然后手动支持从mysql中每隔一定时间,自动加载新的词库
(2)基于ik分词器原生支持的热更新方案,部署一个web服务器,提供一个http接口,通过modified和tag两个http响应头,来提供词语的热更新
用第一种方案,第二种,ik git社区官方都不建议采用,觉得不太稳定
十一、ICU分词器
ICU Analysis插件是一组将Lucene ICU模块集成到Elasticsearch中的库。
本质上,ICU的目的是增加对Unicode和全球化的支持,以提供对亚洲语言更好的文本分割分析,还有大量对除英语外其他语言进行正确匹配和排序所必须的分词过滤器。




